Executive Summary
Over the past few years, artificial intelligence has moved from the fringes of innovation labs into the core of enterprise decision making. Models now influence credit decisions, fraud detection, customer interactions, pricing, and operational automation. For many organisations, AI is no longer experimental;it is operational.
There is some real progress: more organizations are moving beyond isolated pilots and seeing tangible returns. Still, a critical gap remains. While proofs of concept have matured and production deployments are increasing, scaling AI reliably across teams and business units remains difficult. Latest research shows persistent challenges around governance, data readiness, organizational alignment, and trust continue to slow broader adoption and impact.
This is not primarily a technology problem. Most large organisations have access to capable tools, skilled practitioners, and growing volumes of data. The challenge lies elsewhere: enterprises are attempting to run AI initiatives without the operating capability required to manage them at scale.
This challenge became clear in our work with a major UK retail and commercial bank. With over 19 million customers, the organisation is a leading mortgage lender and the number one commercial bank in the UK, employing more than 60,000 people across offices and delivery centres in the UK, Poland, and India. Despite substantial investment in cloud infrastructure and AI/ML driven initiatives, much of this effort had yet to translate into measurable business value.
GlobalLogic was invited to partner with the bank and AWS to redefine its enterprise approach to managing the machine learning lifecycle. The objective was not to introduce new tooling for its own sake, but to establish a repeatable, secure, and scalable operating model for developing, governing, and running ML systems across the organisation.
1. Background: Why AI Struggles to Scale in Enterprises
1.1 Familiar Symptoms Across Industries
Across regulated and unregulated sectors alike, a similar pattern emerges as AI adoption grows:
- Numerous proofs of concept, pilots, and exploratory models
- Long and unpredictable paths from development to production
- Different teams solving the same problems in different ways
- Rising cloud and platform costs with limited transparency
- Governance and risk processes applied late, often as a blocker rather than an enabler
Individually, none of these issues are surprising. Together, they signal a deeper structural challenge.
Importantly, these symptoms are not a reflection of weak talent or poor intent. In most cases, they emerge organically as organisations move faster on experimentation than on operational readiness.
1.2 The Underlying Mismatch
At the heart of the problem is a mismatch between how AI is developed and how enterprises operate.
Experimentation does not translate automatically into operations.Data science workflows are designed to explore, test, and iterate. Enterprise systems, by contrast, require reliability, accountability, traceability, and resilience. Without a deliberate bridge between the two, models that work well in isolation struggle to survive contact with production realities.
Delivery is fragmented by design.AI initiatives often originate within individual business units or teams, each optimising locally for speed. Over time, this leads to a landscape of bespoke pipelines, inconsistent standards, and limited reuse, making scale increasingly difficult.
Governance is disconnected from delivery.Risk, compliance, and model governance frameworks typically exist, but outside the day to day development lifecycle. Controls are applied retrospectively, documentation is recreated manually, and assurance becomes slow and adversarial rather than embedded and continuous.
Costs accumulate without visibility.As experimentation grows, so does infrastructure usage. Without clear attribution or guardrails, spend increases in ways that are hard to link to business outcomes making it difficult to prioritise investment or demonstrate value.
Taken together, these challenges explain why many organisations experience AI as a series of isolated successes rather than a scalable capability.
2. Reframing MLOps: From Tooling to Enterprise Capability
MLOps is often introduced as a technical discipline, a set of practices to automate model deployment, testing, and monitoring. While these elements are important, this framing understates its strategic significance.
At enterprise scale, MLOps is not primarily about tools. It is about how an organisation chooses to operate AI.
2.1 What MLOps Actually Enables
When approached deliberately, MLOps defines a shared set of capabilities that span the entire AI lifecycle:
- How models are developed and promoted into production
- How data, code, and experiments are tracked and reproduced
- How governance and risk controls are embedded into delivery
- How models are monitored once deployed
- How costs are understood, attributed, and controlled
- How standardized processes and shared documentation enable AI systems to scale across teams and business units
In this sense, MLOps functions as the connective tissue between innovation and operations. It allows organisations to move faster without sacrificing control, and to scale AI without multiplying risk.
2.2 What MLOps Is Not
To be clear, MLOps is not:
- A single platform or vendor solution
- “CI/CD for models” in isolation
- Something that can be bolted on once models are already in production
Treating MLOps in this way often leads to well engineered pipelines that still fail to address governance, accountability, or cost, and therefore fail to scale.
2.3 Why This Matters at Executive Level
As AI becomes operational, its failure modes shift. The primary risks are no longer experimental accuracy, but:
- Inability to explain or reproduce decisions
- Undetected model degradation
- Inconsistent behaviour across business units
- Rising costs without commensurate value
MLOps does not eliminate these risks, but it provides the structure, visibility, and controls needed to surface, monitor, and mitigate them at scale; without it, they are almost impossible to manage.
Industrialising AI therefore requires a shift in perspective: from delivering individual models to building an enterprise capability that can sustain AI over time.
3. Case Study: Enterprise Grade MLOps at Major UK Bank
For organisations looking to industrialise AI, the central challenge is not access to technology, tools, or talent, but clarity on the operating capabilities that must surround them; the harder task is identifying which of those capabilities are essential for reliable, large-scale AI, and which gaps will constrain growth over time.
This became clear in our work with one of the UK’s largest retail and commercial banks. Despite significant investment in cloud infrastructure and analytics tooling, AI delivery remained slow, fragmented, and difficult to scale. The issue was not tooling, but the absence of shared, enterprise level capabilities that connected experimentation with production.
The bank’s existing development process took 4-6 months to release their models into production and at least 60% of their estimated models were abandoned before project completion.
We partnered with the bank to improve their return on their AI investments and ensure long-term relevance in its machine learning efforts. A useful way to approach this challenge is to shift the conversation away from platforms and toward enterprise capabilities.
Typically a successful enterprise grade MLOps capability spans six interconnected capabilities.
3.1 Lifecycle Management
At scale, the ability to move models from idea to production must be predictable and repeatable, not dependent on individual teams or bespoke processes.
Lifecycle management covers:
- Standardised development workflows across teams
- Consistent environments from development through production
- Clear promotion paths with defined quality and risk gates
At the UK bank, the absence of these foundations meant that moving from idea to production routinely took more than twelve months. Each business unit followed its own development approach, environments differed from team to team, and promotion into production relied heavily on manual coordination. As a result, most initiatives stalled long before deployment not because the models failed, but because the organisation lacked a reliable route to production.
When lifecycle management is weak, delivery timelines become unpredictable and operational ownership is unclear. On the other hand, when it is strong, organisations gain confidence that AI initiatives can progress without constant reinvention.
For senior leaders, this translates into delivery reliability: fewer surprises, clearer accountability, and a more stable pace of change.
3.2 Governance by Design
In many organisations, governance processes sit outside the development lifecycle. Reviews happen late, documentation is assembled manually, and controls are perceived as obstacles to progress.
Enterprise grade MLOps integrates governance directly into how models are developed and deployed:
- Policies are encoded into delivery workflows
- Approval processes align with risk, not convenience
- Documentation and evidence are generated automatically as part of delivery
- Principle of Least Privilege for data access with self serve requests
At the bank, governance friction was one of the primary reasons AI initiatives took a long time to become reality. Controls were applied retrospectively, often after months of development, leading to rework, delays, and frustration across teams. Embedding governance into delivery did not reduce oversight. It made oversight continuous and scalable.
For leaders, governance by design reduces both risk exposure and delivery friction, a combination that is difficult to achieve through process alone.
3.3 Reproducibility and Auditability
As AI systems influence real world decisions, the ability to explain how a model was built becomes as important as what it predicts.
Reproducibility and auditability ensure that:
- Experiments, data, code, and models are versioned and traceable
- Decisions can be reconstructed after the fact
- Models can be confidently reviewed, challenged, or rolled back
This capability is often underestimated until it is needed typically during regulatory review, incident investigation, or internal assurance.
This gap was particularly visible in the preliminary phases of work at the bank. Model Risk Management processes had evolved around traditional quantitative models and operated largely independently from emerging ML development practices. Evidence was recreated manually, traceability was inconsistent, and assurance processes were slow and labour intensive.
From an enterprise perspective, reproducibility is not only about technical efficiency, it is also about institutional memory and defensibility.
3.4 Operational Monitoring
Once deployed, models do not stand still. Data changes, behaviours shift, and performance can degrade in subtle ways.
Operational monitoring involves systematically collecting model predictions, input data signals, and outcome metrics in production, and using these to detect performance degradation, data drift, or unexpected behaviour over time.
Operational monitoring ensures organisations can:
- Track model performance over time
- Detect data drift and unexpected behaviour
- Respond to issues before they affect customers or operations
Before establishing shared MLOps foundations, models at the bank were deployed across multiple systems with no consistent way to monitor performance. Reviews were manual, refresh cycles were irregular, and accountability for ongoing model health was unclear.
Without this capability, AI systems operate as black boxes in production. With it, organisations gain the confidence to rely on AI in business critical processes.
This is often the inflection point where AI moves from “interesting” to operationally trusted.
3.5 Cost Transparency and Sustainability
As AI adoption grows, so does infrastructure usage. Without deliberate controls, costs accumulate in ways that are difficult to attribute or justify.
Cost transparency enables:
- Visibility into spend by use case, team, or environment
- More informed prioritisation decisions
- Guardrails that encourage responsible experimentation
The bank’s cloud investment had grown rapidly, but leadership lacked clear visibility into which initiatives were delivering value and which were not. This made it difficult to prioritise funding or demonstrate returns.
This capability is not about restricting innovation. It is about ensuring that AI investment behaves like a managed portfolio rather than an open ended expense.
For executives, cost transparency is often the difference between continued investment and stalled programmes.
3.6 Self-Service with Guardrails
Finally, scale depends on enabling teams to move quickly without increasing risk or inconsistency.
Self-service with guardrails provides:
- Reusable templates and patterns
- Secure, pre-approved environments
- Clear standards that reduce cognitive load
At the bank, data scientists were frequently expected to manage deployment pipelines, cloud infrastructure, and security controls tasks far outside their core expertise. Data Scientists relied on infrastructure teams having to contact them anytime they wanted to make a change. This slowed delivery and increased frustration.
By contrast, self-service platforms with embedded guardrails allow multiple teams to deliver AI solutions in parallel while maintaining a coherent enterprise approach.
When done well, self-service reduces dependency on central teams without sacrificing control. When done poorly, it accelerates fragmentation.
Why This Capability View Matters
These six domains are deeply interconnected. Weakness in one area tends to surface elsewhere for example, strong experimentation without cost transparency, or governance without operational monitoring.
Organisations that succeed in industrialising AI do not attempt to perfect all capabilities at once. Instead, they:
- Understand their current maturity
- Prioritise gaps based on risk and value
- Build capabilities iteratively, informed by real use cases
This capability first perspective provides a practical foundation for deciding where to invest, how to sequence change, and how to measure progress.
The question, then, is not whether to invest in MLOps but how to start in a way that delivers learning and value without overengineering from day one.
That requires treating MLOps as a journey, not a one-off implementation.
4. Starting the Journey: Foundations Before Scale
Once organisations recognise the need for enterprise grade MLOps, the instinct is often to search for a comprehensive platform solution. In practice, the organisations that succeed take a more deliberate approach, they treat platforms as enablers, not endpoints, balancing speed with control and building operational capabilities incrementally rather than attempting to design a perfect end state upfront.
This was the approach GlobalLogic took when partnering with a major UK retail and commercial bank. The goal was not to introduce tooling for its own sake, but to create a repeatable, secure, and scalable pathway for taking machine learning from experimentation into production and to do so in a way that could be adopted consistently across teams and business units.
To support this, GlobalLogic drove the adoption of a modern, self-service MLOps platform designed to be secure, scalable, and sustainable, enabling the development and productionisation of ML based services using AWS SageMaker.
Beyond providing an integrated data science environment, the platform was programmed to orchestrate machine learning models, data, and outcomes across the full lifecycle, while also enabling access to deployment diagnostics, model health indicators, and the governance and business metrics required by teams operating across the ML SDLC.
4.1 Assess Before You Build
The engagement began with an assessment of how machine learning was actually being delivered across the organisation. While tooling existed, there was no consistent or predictable path from experimentation to production. Models were developed in isolation, environments varied across teams, and deployment processes depended heavily on manual intervention and individual expertise.
GlobalLogic worked with data science, engineering, platform, and risk teams to map the end-to-end ML lifecycle as it operated in practice. This included understanding how models were reviewed, how approvals were obtained, how evidence was generated for governance purposes, and where handoffs introduced delay or uncertainty. The goal was not to produce a maturity score, but to identify the specific points where progress slowed or stalled altogether.
This assessment created a shared understanding of why delivery timelines were unpredictable and why so many initiatives failed to reach production, despite strong underlying ideas and investment.
4.2 Deliberate Selection of Use Cases
Upon the start of the engagement, the bank already had some potential use cases to be realised into production. Rather than attempting to standardise all machine learning activity at once, early MLOps adoption was anchored to a small number of representative use cases. These were selected to reflect both meaningful business value and the types of delivery and governance challenges the bank faced most frequently.
By grounding early implementation in real workloads, it was ensured that MLOps capabilities were shaped by practical requirements rather than just theoretical best practice. This allowed patterns for deployment, approval, monitoring, and rollback to be tested and refined in realistic conditions before being scaled more widely.
This sequencing also reduced risk. Early successes helped build confidence across teams and created momentum for broader adoption, while lessons learned could be incorporated before standards were applied more broadly.
4.3 Build Foundations That Enable Iteration
With priorities established, the focus shifted to establishing a small set of foundational capabilities that could support immediate delivery while remaining flexible over time. Rather than optimising for completeness, the emphasis was on repeatability, consistency, and integration with existing operating constraints.
Standard development and deployment templates were introduced to reduce variation across teams and business units. These templates provided a clear route from development through testing into production, with quality and governance checks embedded into the process rather than applied retrospectively. This reduced reliance on bespoke solutions and removed many of the manual steps that had previously slowed delivery.
Crucially, these foundations were designed to evolve. As adoption increased and new requirements emerged, additional automation, controls, and observability could be layered in without forcing teams to rework existing solutions. This allowed the platform and operating model to mature in step with real usage.
4.4 Treat MLOps as a Product, Not a Project
A key factor in sustaining progress was how MLOps was positioned internally. Rather than being treated as a finite implementation, it was managed as a long-lived capability with clear ownership and an evolving roadmap.
GlobalLogic supported the bank in establishing a product-oriented mindset, ensuring that feedback from consuming teams informed ongoing improvement. Training and enablement were integral to this approach. Data scientists were onboarded onto standard workflows and self-service capabilities that reduced dependency on central teams while maintaining consistent controls.
This model ensured that MLOps remained aligned with both delivery needs and governance expectations as adoption expanded across the organisation.
4.5 Accelerating With Reference Architectures
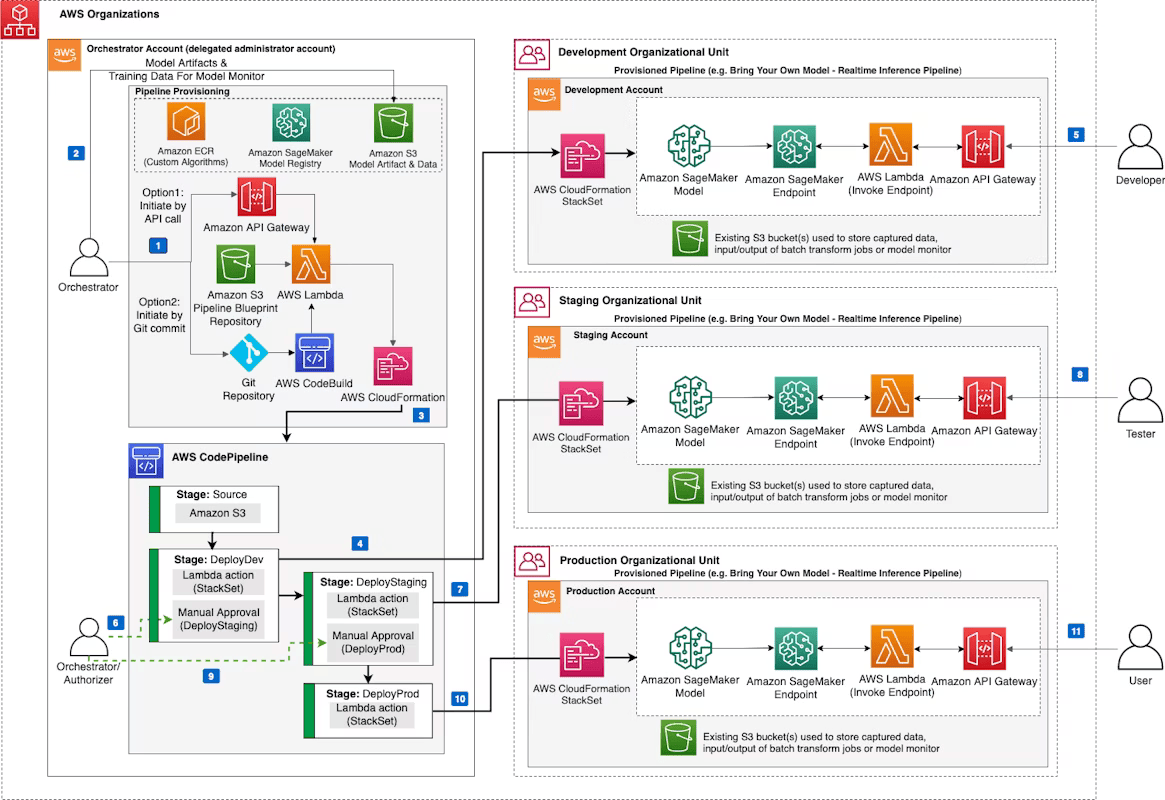
Source: AWS Sagemaker
With foundations in place, cloud native AWS reference architectures were used as a means of acceleration rather than prescription. Proven patterns helped reduce design effort and provided a common baseline for teams, but they were adapted to reflect the bank’s operating model and regulatory context. AWS provides many reference architectures and design patterns for MLOps which can be used as a starting point for a comprehensive environment design.
By treating reference architectures as starting points, the organisation avoided over-engineering early solutions or becoming locked into rigid designs. This approach balanced speed with flexibility, allowing teams to move faster while retaining the ability to adapt as requirements evolved.
The result was an MLOps capability that could scale across teams and use cases without recreating the fragmentation that had previously limited progress.
5. What Industrialised MLOps Enables
When MLOps is treated as an enterprise capability rather than a technical afterthought, its impact extends well beyond engineering efficiency. At the bank, the most meaningful outcomes were organisational: how confidently, consistently, and sustainably machine learning could be applied across the business.
By modernising the ML development lifecycle, we helped the bank improve model quality, standardise delivery, and reduce friction between teams. Over time, this translated into measurable gains in speed, predictability, and trust while significantly reducing operational risk and cost.
5.1 Faster and More Predictable Delivery
With industrialised MLOps in place, delivery became repeatable and predictable. Standard workflows, automated promotion paths, and embedded governance reduced uncertainty and eliminated many of the delays that previously stalled projects. As a result, development-to-deployment timelines were reduced to between one and three weeks for production ready use cases.
The organization significantly accelerated delivery timelines across the board. End-to-end solutions that previously took around 12 months were delivered in under 3 months. Data discovery and access improved from roughly 5 days to less than 1 day. ML models that once took 6 months to reach production were deployed in under 2 weeks, and self-service environments that previously required more than 40 days were provisioned in less than a day.
Importantly, this acceleration did not come at the expense of control. Instead, it gave leadership greater confidence in planning and prioritisation across portfolios of AI initiatives.
5.2 Scalable Adoption Across Teams and Business Units
Before MLOps was established as a shared capability, each business unit had developed its own way of working. As adoption grew, this fragmentation made it increasingly difficult to scale AI consistently across the organisation.
Industrialised MLOps reversed this trend. Common patterns, workflows, and standards allowed multiple teams to deliver in parallel without reintroducing inconsistency. Reusable templates, self-service capabilities and training material reduced duplication of effort and lowered the barrier to entry for new teams.
Over time, this enabled the bank to move from isolated successes toward a more coherent, enterprise wide approach to AI delivery, one that could scale without sacrificing quality or control.
5.3 Increased Trust and Operational Confidence
One of the most significant shifts was in how AI systems were trusted once deployed. Previously, models often ran in production with limited visibility into performance or ownership, making it difficult to detect degradation or intervene when issues arose.
By embedding traceability, monitoring, and governance into the MLOps lifecycle, the bank gained far greater operational confidence. Models could be explained and reviewed when required, performance could be tracked over time, and changes could be made in a controlled and auditable manner.
This confidence enabled the bank to deploy machine learning in more business critical contexts not because risk had been eliminated, but because it had become visible and manageable.
5.4 Better Alignment Between Innovation and Governance
With mature MLOps practices in place, governance became embedded into delivery workflows. Evidence required for Model Risk Management and compliance was generated automatically as part of the development lifecycle, and approval processes aligned more closely with actual risk.
This shift improved collaboration between data science, engineering, and risk teams. Governance became more proactive, approvals more efficient, and discussions more grounded in data rather than assumptions reducing friction while strengthening oversight.
5.5 Improved Economic Discipline and Sustainability
As machine learning adoption expanded, so too did the need for financial clarity. Previously, cloud usage and experimentation costs were difficult to attribute to specific teams or outcomes, making it challenging to assess return on investment.
Industrialised MLOps introduced greater transparency across the ML lifecycle. Leaders gained clearer visibility into where resources were being consumed, how costs aligned with value, and which initiatives justified further investment.
This discipline did not constrain experimentation. Instead, it ensured that experimentation occurred within a framework that supported long-term sustainability helping unlock continued investment beyond early pilots.
What These Outcomes Have in Common
Taken together, these outcomes reflect a shift in how AI is perceived and managed:
- From experimentation to operation
- From isolated projects to shared capability
- From reactive control to embedded governance
Industrialised MLOps does not guarantee AI success. What it provides is something more fundamental: the ability to learn, adapt, and scale with confidence.
The last step is not technical, but strategic: recognising that industrialising AI is a leadership challenge as much as an engineering one.
6. From AI Ambition to Enterprise Reality
For many organisations, the ambition for AI is clear. The intent is there, the investment has begun, and early successes exist across pockets of the business.
What is less clear is how those successes translate into a sustained, enterprise wide capability.
Industrialising AI does not require abandoning experimentation or slowing innovation. It requires recognising that, beyond a certain point, AI must be operated with the same discipline applied to other critical enterprise systems.
This shift is as much about leadership as it is about technology.
It involves:
- Accepting that AI introduces new forms of operational and regulatory risk
- Aligning innovation with governance rather than treating them as competing forces
- Investing deliberately in shared capabilities rather than isolated solutions
MLOps provides the foundation for this shift. Not as a platform to be implemented once, but as a capability to be developed, evolved, and owned over time.
Organisations that make this transition are better positioned to:
- Scale AI responsibly across teams and business units
- Respond confidently to scrutiny from regulators, customers, and internal stakeholders
- Sustain investment by linking AI activity to measurable outcomes
Those that do not often find themselves revisiting the same challenges repeatedly adding controls after incidents, rebuilding pipelines to meet new requirements, and questioning why early promise has not translated into lasting impact.
What separates early progress from lasting impact is execution at the enterprise level.
A Practical Next Step
For most organisations, the question is not whether MLOps matters, but where to start.
A pragmatic first step is to establish a shared view of current maturity and priorities:
- Which MLOps capabilities already exist, even informally
- Where gaps create the greatest risk or friction
- Which use cases are most likely to benefit from industrialisation
This clarity enables leadership teams to make informed decisions about sequencing, investment, and ownership before scale makes change more difficult.
Industrialising AI is a journey. The earlier it is approached deliberately, the more value it is likely to deliver.